ASCII的诞生
由于计算机最基本的单位是bit,只能记录0和1,于是人们想到了将复杂的字符与数字一一映射,从而从数字知道所要表示的内容。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新是在1986年,共定义了128个字符(编号从 0 至 127)。
Extended ASCII
ASCII的局限在于只能显示26个基本英文字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)
有人开始使用128至255编码重音符号等,这就产生了Extended ASCII。
Unicode
Unicode的产生
尽管256个字符适合大部分的国家,但是像中国这样的国家,它们的字符的数量远远大于256种,于是,人们必须进一步扩大数字与字符的映射表,才能进一步的满足计算机表示的需求,Unicode应运而生。
早期的Unicode曾使用2 bytes,也就是16 bits编码字符,这样可以有 65536 个不同的编码,目标是囊括所有人类语言的所有文字。
后来发现65536个编码不够用。当今的Unicode范围为: 0 – 1,114,111 (0x10ffff)
Unicode的基本概念
The Unicode standard describes how characters are represented by code points.
code points 是什么能?它就是一个数字,这个数字能够独一无二的表示一个字符。它通常使用16进制来表示的
In the standard, a code point is written using the notation U+12CA to mean the character with value 0x12ca (4810 decimal).
Unicode是如何显示出来人类能够读懂的字符
正如前面的介绍一样,Unicode是一系列的十六进制的数字,但是为什么我们平时看到的是字型呢?这里面涉及到了另外的一个机制,将数字展示为字型,涉及一个软件的GUI设计,不进行深入的介绍。
Most Python code doesn’t need to worry about glyphs; figuring out the correct glyph to display is generally the job of a GUI toolkit or a terminal’s font renderer
encoding
一个Unicode string代表的是一串十六进制的数字。为了保存下来,我们必须设置一个过程,将这些十六进制的数字转换为二进制的数字,从而保存下下来。这个过程叫编码(encoding)。
A Unicode string is a sequence of code points, which are numbers from 0 to 0x10ffff(十进制: 1,114,111 )
This sequence needs to be represented as a set of bytes (meaning, values from 0–255) in memory.
The rules for translating a Unicode string into a sequence of bytes are called an encoding.
32-bit integer编码
我们将”python”编码为可储存的二进制的形式
缺点:
- 计算机中存储的数据大部分的Unicode都在0~255之间,这样造成了极大的空间浪费
- 和原来的的C语言中的strlen()函数有冲突。
utf-8编码
和之前的编码方式相比,utf-8编码的长度是可以变化的。
- 若code point<128,那么用1byte的二进数来储存这个字符
- 若128<=code point<=2047 (0x7ff)用2bytes
- 若code point>2047,将会用3个或者是4个bytes来表示,每一个byte表示的范围都在128~255之间(想想为什么)。
前面的想一想:如果三位或者是四位有一个byte表示在0~127之间,那么它到底是一个字节还是和三个字节表示一个整体呢?因此用这种规定来避免这种冲突,从而很容易判断哪些byte是一个整体
Python2.7与Unicode
python2.7内的字符串的类型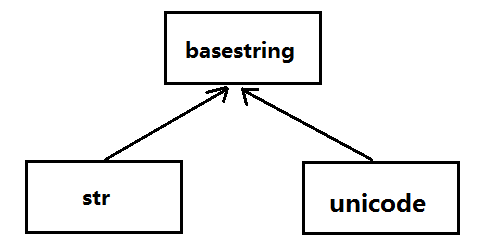
- Python 2.7中,str表示8位文本(8-bit string)和二进制数据;unicode表示Unicode文本
注意,在Python2中,若有下面的代码,则会报错,原因str类型保存的是八位文本
|
|
但是,下面的代码又是对的,注意区别:
一些操作的代码,注意操作的环境在Python2.7中进行
用于解码的 Built-in Function:unicode()
格式:
unicode(string[, encoding, errors])
encodeing表示的是原来的编码的方式,参数可以有utf-8,GB2312等等,若不填任何的参数,那么默认的encoding = ‘ASCII’. errors = ‘strict’(如有错误就会报错)或’repalce’(无法识别的会替换成+UFFFD,也是我们平时经常见到了一个黑色的菱形中间有一个问号的符号)或’ignore’(跳过这个编码数字)
|
|
Unicode string的用于编码的方法:encode()
格式:
str.encode([encoding[,errors]])

上面的图片很好的解释了之前讲过的utf-8编码的可变长度的特性
再次回顾:
和之前的编码方式相比,utf-8编码的长度是可以变化的。
若code point < 128,那么用1byte的二进数来储存这个字符
若128 <= code point <= 2047 (0x7ff)用2bytes
若code point > 2047,将会用3个或者是4个bytes来表示
8-bit string的用于解码的方法:str.decode()
直接上代码:
说明:utf8_version保存的是8-bit string,这种类型是用来将数据保存到文件中的。然后将其解码,解码的方式是utf-8,最后又转变成了unicode类型。
是否可以对str对象使用encode()方法?
str.encode() 实际上等价于:
str.decode(sys. getdefaultencoding()).encode()
而 sys.getdefaultencoding() 一般是ascii
不要对str对象使用encode,不要对unicode对象使用decodestr.decode()和unicode.encode()是正规的用法
深刻理解python2.7里面的str和unicode类型的区别
引号前是否有前缀 u 只是书写、显示时的表象。透过表象,进一步来看:
str表示8位文本(8-bit string)和二进制数据
unicode表示Unicode文本(Unicode string)
str对象是一个“byte序列”( sequence of bytes );而unicode对象是“character序列”(sequence of characters),也可理解为sequence of code-points
Character或其在Unicode中的表示形式code point只是概念上的东西,计算机存储、传输信息需要以byte形式进行。这就是需要对unicode对象进行编码的原因
utf-8与gbk2312的区别:
utf-8由于是针对世界上所有的文字,所以在处理中文的时候大多数编码成3bytes,而是用gbk2312编码的话,中文编码为2bytes,因此gbk2312更适合中国文字的存储。
Python 3.5与Unicode
- str类型支持Unicode,或者说Python3.5中的str类型就相当于Python 2.7中的unicode类型
str对象没有decode()方法,因为此时的str类型表示的就是python2的unicode类型。
Python 2.7 包括两种数据类型:str 和 unicode
Python 3.5 相对应的数据类型:bytes 和 str在Python 3.5中, “bytes” 类型存储的是 byte 串。可以通过一个 b 前缀来声明 bytes
推荐链接
unicode前世今生
前文的中文翻译
unicode
python3官网对unicode的说明
python2官网对unicode的说明